UI 상태 관리를 할 때 어떤 것들을 고려할 수 있을까
요약
- 구성 변경이란 onDestroy로 인스턴스가 소멸되고 onCreate부터 새 인스턴스가 생성되는 것이다.
- 구성 변경이 일어날 수 있는 여러 상황이 있다.
- 구성 변경이 일어날 때 data를 유지할 수 있는 방법으론 크게 3가지가 있다.
- 로컬 DB (SharedPreference, DataStore, Room)
- 뷰모델
- SavedInstanceState (SavedStateHandle)
- 구성 변경이 일어날 때 동작하는 콜백이 있고 이 콜백 안에서 어느 요인해 의해 변경이 일어났는지 파악해볼 수 있다.
- 구성 변경이 일어나지 않게 제한할 수 있다.
내용

이 표 하나가 많은 걸 알려주고 있다. 공식문서에 프로세스에 의한 kill 경우를 대놓고 소개해주고 있었다. 마음이 쓰리지만 이제라도 알 수 있어서 다행이다.
뷰모델
ViewModel은 메모리에 데이터를 보관하므로 디스크 또는 네트워크에서 데이터를 검색할 때보다 비용이 낮습니다. 구성 변경 중에는 메모리에 남아 있으며 시스템이 구성 변경으로 인한 새 활동 인스턴스와 ViewModel을 자동으로 연결합니다. 사용자가 활동 또는 프래그먼트를 종료할 때 또는 개발자가 finish()를 호출할 때 ViewModel은 시스템에 의해 자동으로 폐기됩니다.
공식 문서에 위 내용이 있는데 "재생성이 될 때나 finish()나 똑같이 onDestroy()를 타는데 왜 재생성은 뷰모델 인스턴스가 죽지 않고 자동으로 연결되지?"라는 의문이 들었다.

간단하게는 재생성이 될 때와 finish()를 할 때가 구분이 된다고 말할 수 있다.
"그렇다면 뷰모델이 자동으로 연결되는 원리는 뭐지?"라는 추가 의문이 들었는데
뷰모델은 VIewModelStore라는 클래스 안에 map 형태로 관리되며 캐싱을 하여 기존에 생성돼있던 인스턴스가 있으면 가져다 사용하고 없으면 생성 후 캐싱을 해두는 식이었다.
"그렇다면 구체적으로 프로세스가 어떤 경우에 어떤 것들을 어떤 방식으로 kill 하는 것일까?"라는 의문이 따랐다.

공식 문서를 읽던 중 관련 내용을 보았다. 프로세스의 상태는 4가지인데 어떤 상태에 놓여있냐에 따라 다르다고 한다. 자세한 내용은 다음 링크를 참고하라고 하는데 이 부분은 나중에 다뤄보겠다. (추가 참고 포스팅)
onSaveInstanceState() vs SavedStateHandle
ViewModel에서 시스템이 시작한 프로세스가 종료된 후 데이터를 다시 로드하려면 SavedStateHandle API를 사용하세요. 데이터가 UI와 관련되어 있고 ViewModel에 유지할 필요가 없는 경우에는 뷰 시스템의 onSaveInstanceState()를 사용하세요.
참고로 SavedStateHandle은 intent로 data를 넘겨받아 viewmodel에 세팅해주는 과정을 생략 가능하게 해준다고 한다.
뷰모델이 kill 당했을 때 SavedStateHandle를 사용하지 않는다면 저장된 인스턴스 상태에 저장된 쿼리를 뷰모델로 전달해야 한다고 한다.
onSavedInstanceState()

onSavedInstanceState에는 보통 스크롤 위치 등을 저장한다고 한다.
아래는 공식 문서 내용이다.
- onSaveInstanceState(Bundle)는 액티비티가 종료되기 전에 호출되어, 나중에 복원할 수 있도록 상태를 저장하는 메서드이다.
- 이 상태는 나중에 onCreate(Bundle) 또는 onRestoreInstanceState(Bundle)에서 다시 전달되어 사용된다.
- 사용자와 상호작용하지 않을 때 항상 호출되는 onPause와 달리 액티비티 인스턴스가 다시 복원될 가능성이 있을 때만 호출되며, 모든 경우에 호출되지 않는다.
- 예를 들어, 액티비티 A에서 B로 이동한 뒤 사용자가 다시 A로 돌아오는 경우, B의 인스턴스는 복원되지 않으므로 onSaveInstanceState(Bundle)는 호출되지 않습니다. 반면, B가 실행 중일 때 시스템이 자원을 회수하기 위해 A를 종료한다면, A의 상태는 저장되어야 하므로 onSaveInstanceState(Bundle)가 호출된다.
- 기본적으로 View의 상태는 자동으로 저장되고 복원되지만, 추가적인 데이터를 저장하고 싶다면 이 메서드를 재정의하여 처리할 수 있다.
- Android 9 (Pie) 이상에서는 onStop() 이후에 호출되며, 그 이전 버전에서는 onStop() 이전에 호출될 수도 있고, onPause() 이전이나 이후에 호출될지 보장되지 않는다.
직렬화, 역직렬화, Bundle
저장된 인스턴스 상태 번들은 구성 변경 및 프로세스 종료 시에도 유지되지만, 데이터를 직렬화하기 때문에 저장용량 및 속도의 제한이 있습니다. 직렬화될 객체가 복잡하면 직렬화 시 많은 메모리가 소비될 수 있습니다. 직렬화 프로세스는 구성 변경 시 기본 스레드에서 발생하기 때문에 장기적으로 실행되면 프레임 하락 및 시각적인 끊김 현상이 발생할 수 있습니다. 원시 유형 및 String 같은 단순하고 작은 객체만 저장해야 합니다.
"직렬화 프로세스는 구성 변경 시 기본 스레드에서 발생" 이 부분은 추후 자세히 다뤄보도록 하겠다.
직렬화 : 객체를 일련의 바이트 형태로 변환하는 과정
ex) Dog("BINGO", 3, "black") -> {"name":"BINGO", "age":"3", "color":"black"}
*변환 과정에서 메모리가 소비됨
역직렬화 :
ex) {"name":"BINGO", "age":"3", "color":"black"} -> Dog("BINGO", 3, "black")
bundle에 primitive type이 아닌 data를 저장할 땐 직렬화된 값을 넣어주어야 하며 다시 읽어질 때 역직렬화를 통해 복원된다.
bundle에 대해서 알아보다보니 대뜸 Activity 간에 intent를 통해 data를 공유할 때 왜 객체를 직렬화시켜주어야 하는지 궁금해졌다.
간단하게는 intent의 putExtra 메서드에서 내부적으로 bundle을 사용하고 있기 때문이다.
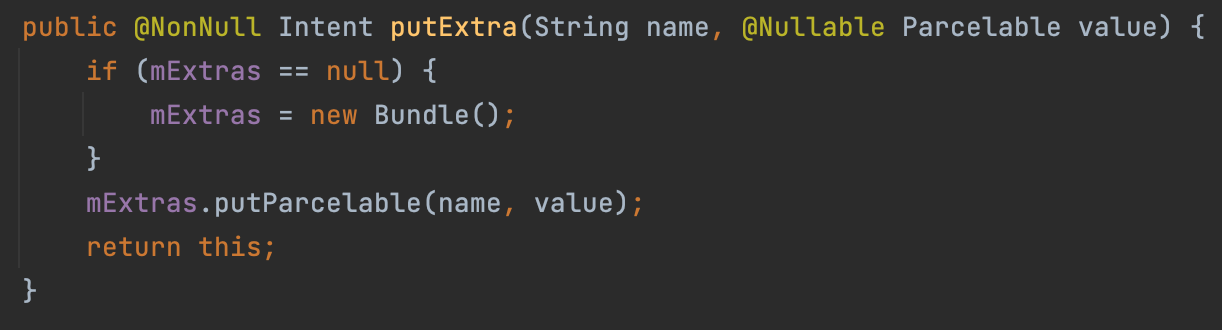
메모리 주소 0x1234에 객체가 저장되어 있다고 해도, 다른 곳에서는 그 메모리 주소가 다른 데이터를 가리키거나 아예 접근할 수 없는 메모리 영역일 수 있습니다. (링크)
위와 같은 내용도 있는데 fact인지는 확인이 필요하다. 추후 다뤄보도록 하겠다.
당장은 값 자체를 그대로 전달하는 것이 안정적일 것이란 생각은 있다.
직렬화를 통해 Reference type(참조 형식) 데이터를 Value type(값 형식)처럼 다룰 수 있다.
Value type : 값을 직접 저장하는 데이터 타입이다.
- 스택(stack)에 할당된다.
- Primivite type은 value type의 일종이다.
- 한 변수를 변경해도 다른 변수에 영향을 미치지 않는다.

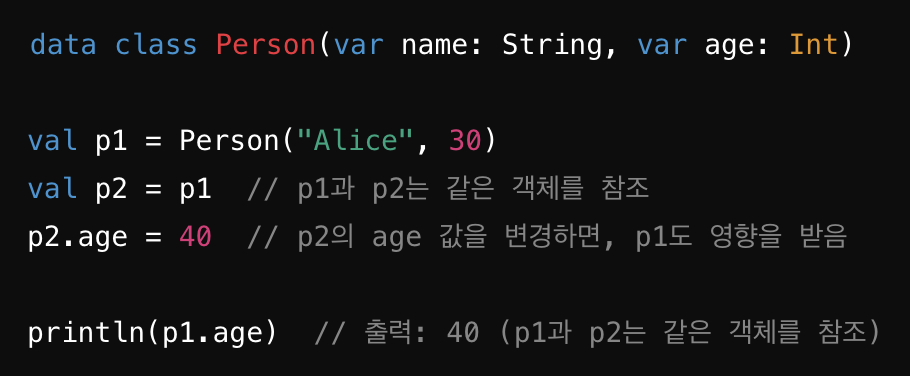
Reference type(참조 형식)은 값이 아닌 메모리 주소(참조)를 저장하는 데이터 타입이다.
- Reference type으로 선언된 데이터는 주로 힙(heap) 메모리에 저장됩니다.
- 이 데이터의 메모리 주소(참조)는 스택(stack) 메모리에 저장되며, 실제 값은 힙에 위치합니다.
- 객체, 배열, 리스트, 맵 등의 복잡한 데이터 구조를 저장하고 처리할 때 값 자체를 복사해서 저장하기보다는 메모리 주소만 참조하는 것이 더 효율적이다.
- 하나의 변수를 통해 데이터를 변경하면 참조를 공유하는 모든 변수가 그 변화를 반영한다.
참고 자료
구성 변경 처리 | Android Developers
Android 앱에서 구성 변경을 처리하세요.
developer.android.com
UI 상태 저장 | Android Developers
구성 변경 시 UI 상태를 유지하는 방법을 알아봅니다.
developer.android.com
ViewModel 개요 | Android Developers
ViewModel을 사용하면 수명 주기를 인식하는 방식으로 UI 데이터를 관리할 수 있습니다.
developer.android.com
[공식 문서] 활동 수명 주기 (process kill etc.)
활동 수명 주기 | Android Developers
활동은 사용자가 전화 걸기, 사진 찍기, 이메일 보내기 또는 지도 보기와 같은 작업을 하기 위해 상호작용할 수 있는 화면을 제공하는 애플리케이션 구성요소입니다. 각 활동에는 사용자 인터페
developer.android.com
데이터 직렬화(serialization)는 무엇이고 왜 필요한가?
우선 이 글은 구글링에서 나오는 여러 가지 직렬화에 대한 글들과 설명들을 읽고 제 나름대로 한번 더 이해하기 편하도록 정리한 글입니다. 데이터 직렬화(serialization), 역직렬화(deserialization)는
hub1234.tistory.com
원시 타입, 참조 타입 메모리 영역
Primitive type(원시타입) vs. Reference type(참조타입)
자바에서 데이터 타입은 크게 두 가지로 나눌 수 있다. Primitive Type(원시 타입) 과 Reference Type(참조 타입) 이 그것이다.
velog.io
'Android > 공식문서' 카테고리의 다른 글
| Glide 공식 문서 읽기 스터디 - 3 (13pg~18pg) (0) | 2025.05.18 |
|---|---|
| Glide 공식 문서 읽기 스터디 - 2 (7pg~12pg) (0) | 2025.05.04 |
| Glide 공식 문서 읽기 스터디 - 1 (~7pg) (0) | 2025.04.28 |
| LifecycleObserver는 왜 쓰는 걸까? (0) | 2024.09.08 |
| 프롤로그 (0) | 2024.09.01 |